In the previous post I discussed how bad it is for proxies to retry. In that post I mentioned offhandedly that the proxy retrying was not only going to make your app slower but also more expensive. This is a first look at that problem.
For your convenience I have created another visualization on GitHub and you can play with it here.
Imagine you have a perfect system and it has constant response time no matter how heavily you load it and it will never drop anything from its queue. If we hit the system with more requests than it can handle it will keep processing requests at that same speed but the responses will be ever more delayed because the requests are stuck in a request queue.
No retries
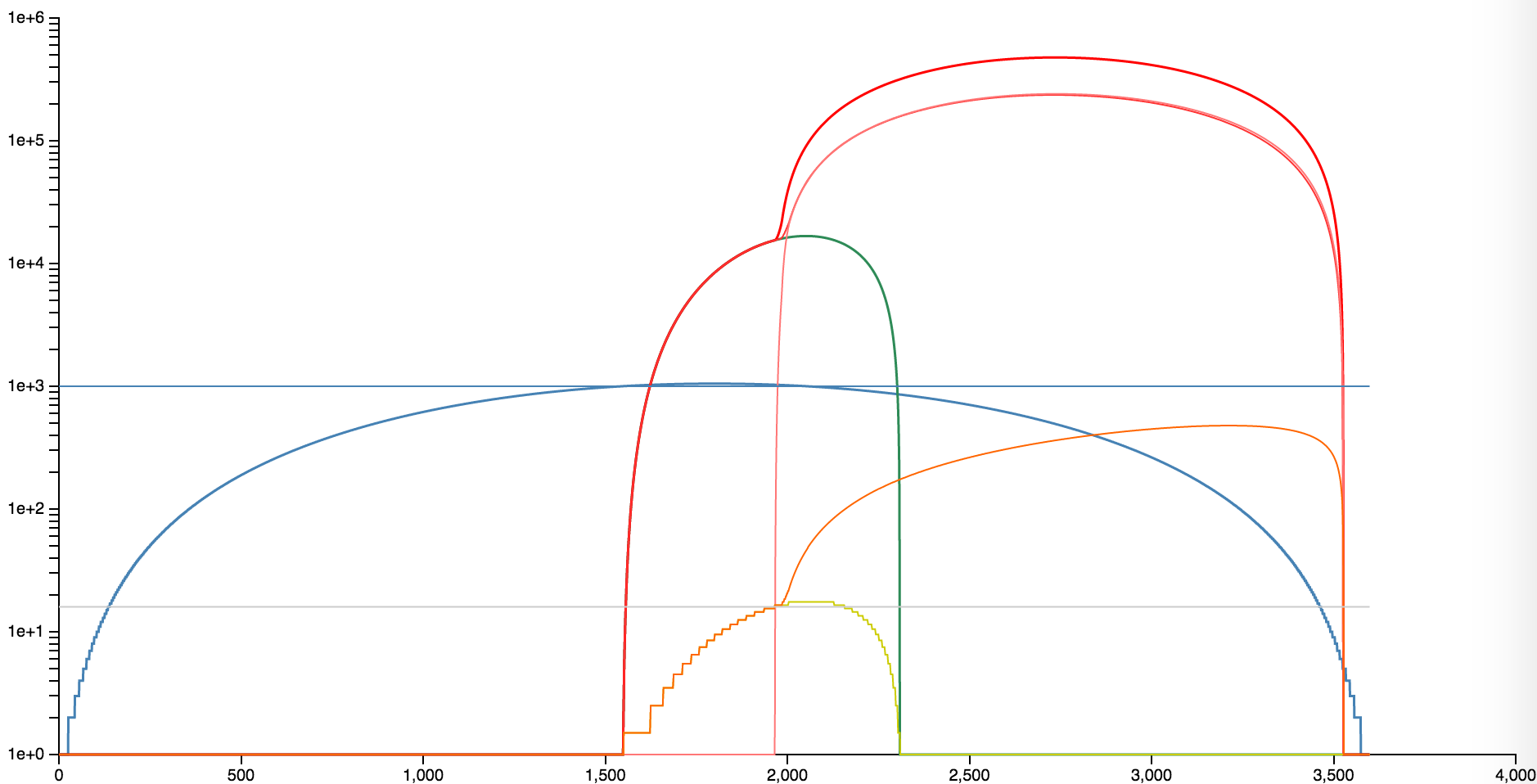
In the no retry case, as we slowly load up the system the total number of requests in the queue eventually exceeds the speed with which they can be processed (about 1500s with default settings). At this point both the queue length and the response time start increasing. Eventually the response time exceeds the timeout on the client (about 1800s with default settings). From the client’s perspective at this point all requests start failing. Note that this situation persists well past the point where the load has dropped below what the system can handle (about 2200s with default settings) because there are still so many – effectively dead – requests stuck in the queue. Only when the queue size drops significantly does the response time drop back below the 15s timeout (about 2350s with default settings) and requests start succeeding again.
All this is bad, but it is expected. One could argue that in this model there is only a problem if we are running very close to the limit of the ability of the system to handle load and that at that point some failures are expected.
With retries
Of course when the request fails it is likely the client will retry. In the simplest case we add a single retry. Everything remain the same until the first timeouts. At this point the number of requests on the system increases significantly because for every request more than 15s old a new request is added to the queue. This can be observed in the steep increase of the overall length of the request queue (bold red line). At the same time the average response time for requests also increases (orange line) because there are now even more (still dead) requests in the queue that need to be processed – and dropped by the client) before recovery can happen.
The thin red lines show the individual contributions of the original requests and the retries. As expected with a single retry these each contribute about half of the overall queued requests. If you look very carfully you will see that the contribution of the original requests initially almost follows the no-retry case but then with the increase of the retries suddenly increases to about the same level as the retries. This may initially seem counterintuitive but can easily be understood if you consider that original requests and retry requests are indistinguishable in the queue and the back end will process them as they come in. In other words, for every retry the back end will not process a first request and as a result more and more original requests will remain in the queue for longer.
To be continued …
I will leave you to ponder the implications of all this while I go off building a couple more models – specifically (1) a model where the system is running with a perfectly fine amount of headroom but gets hit by a requests spike – be it Black Friday or a network outage – and (2) a more realistic model where the response time is not constant with load to give you a more visceral sense of how much headroom a system really needs.