You live in the cloud. Your app lives in the cloud. Mostly. You’ve decided to add access controls via a simple proxy. Your service is supposed to have “100%” uptime, so of course the proxy has to have “100%” uptime.
So far so good – except that the back end only has 99.9% uptime and your friendly ops people have set up alarms that check service uptime via your proxy. Since you don’t want to get dinged you figure you’ll retry. No alarms, no problem. Right?
Truth is you’ve just made your app slower. Probably a lot slower. And more expensive. And less stable.
Huh?
Look at the data
Have a look at this picture. This is a real test for a proxy that retries after 15s.
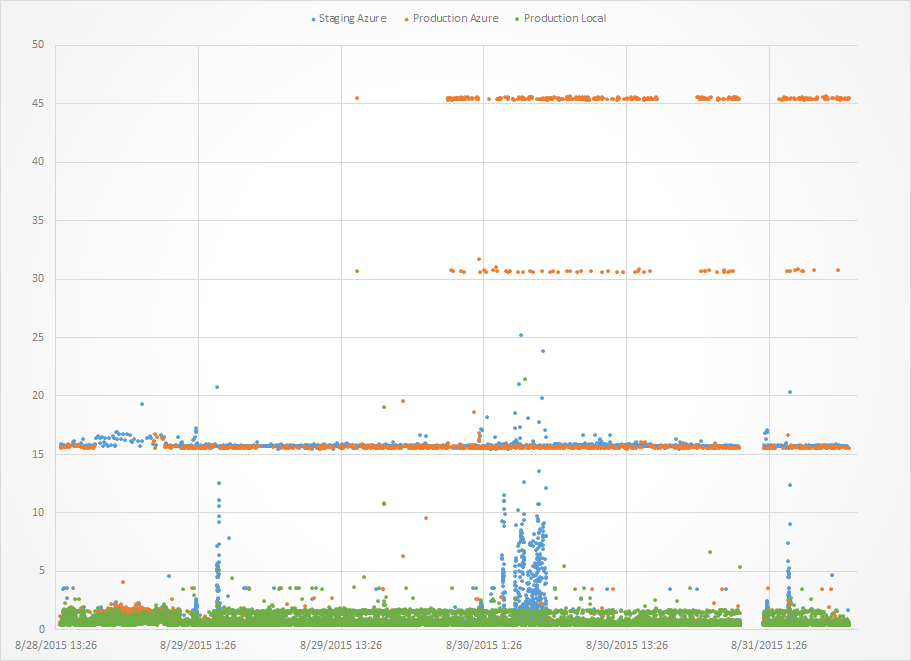
Let’s focus on the orange data. You’ll have to trust me when I say there are orange dots under the green dots. What you see is that the retry works really well: typical response time is about 2s and if that fails we get responses after about 17s (15+2) and if that fails we get responses after about 32s (215+2) and if that fails we get responses after about 47s (315+2). This is great! The proxy works!
Does it though? What should the client do? Should it wait for 50s? Or should it retry retry 25 times after 2s in the hopes that a single call will take the expected 2s? ? 10 times after 5s to account for some spread? Exponential backoff?
Based on the orange lines the client should absolutely retry every 3-5s. Of course that will kill your proxy and back end because under load each of the “timed out” calls will still go through the full proxy/back-end retry cycle. You just made the client DoS your service.
In practice the blue data is more realistic. Under load there is a time spread in service response times. Some calls may take up to 15s and response times generally increase with server load. This is why best practice would suggest exponential backoff. Using exponential backoff may improve the situation because you will eventually wait longer than the first proxy retry but even now the early calls in the backoff sequence are “timing out” on the client but the abandoned client calls still put a load on the backend through the proxy retry pattern so now you are using the proxy to DoS your service. Better but not good.
Finally, in both of the above cases you client contains retry code. Now, why would you have retry code in your proxy?
Slower? I don’t believe you!
Ok. Just for you I have created this cool little toy on GitHub which allows you to walk through this step by step. Let’s say your server takes at least 2s to respond and at most 6s. Let’s model this as a gaussian because they are pretty:
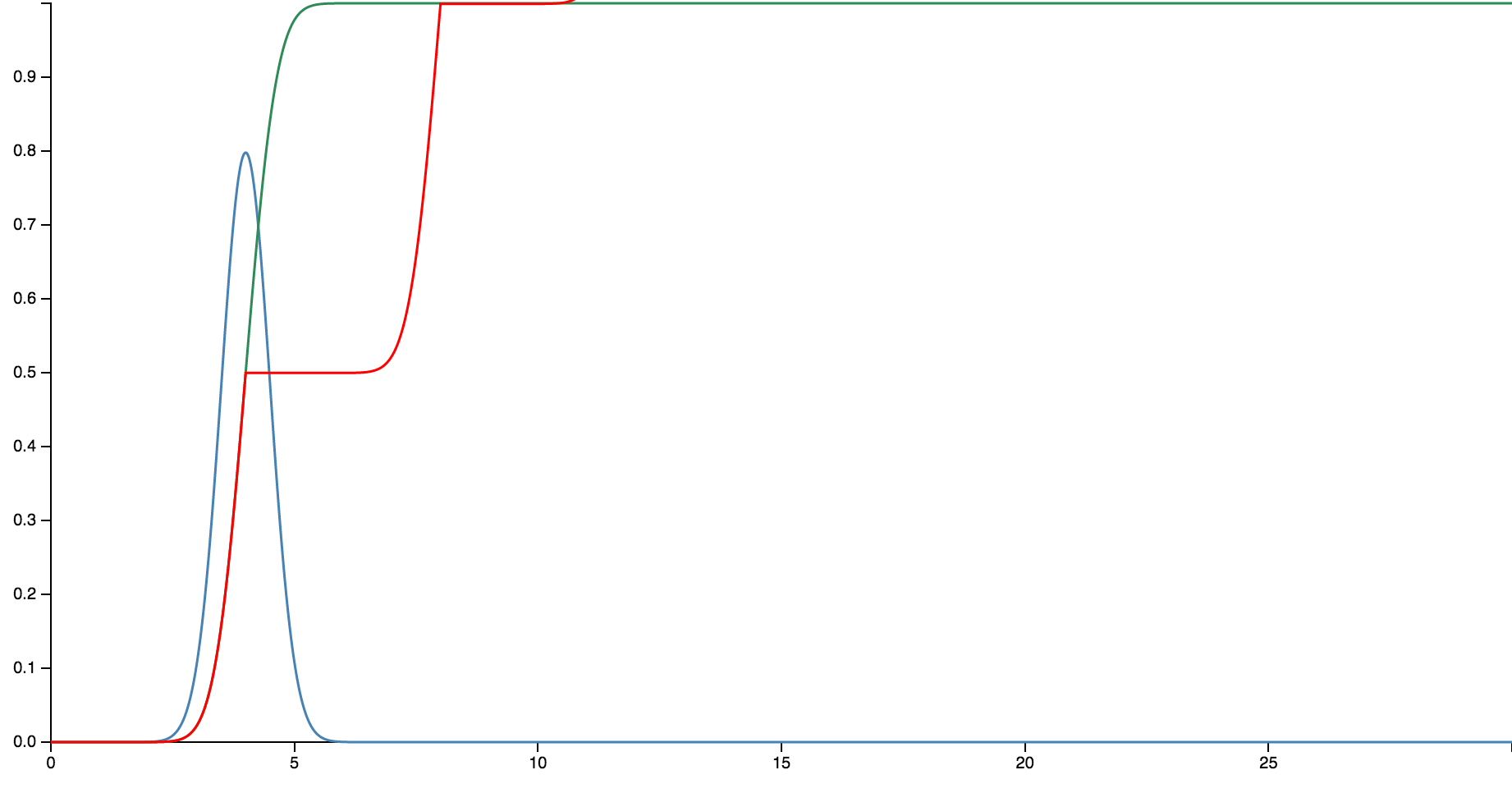
The blue line shows instantaneous probability that your request will be served at this time. The green line is the integrated probability, meaning that your request will be served by this time. Basically at 6s it is all but guaranteed that you received a reply.
So far so good. Now let’s have a look at the red line and what happens if we retry. If we retry early then we give up on any chance of the old request being fulfilled and start the wait again at the beginning. What this shows very nicely is that for any retry before you are guaranteed completion at 6s your performance will get worse.
How’s that different from the client doing the retry? Admittedly it isn’t. Except the client now has to wait until it’s guaranteed that the proxy would return!